This document explains how the default scene graph renderer works internally, so that one can write code that uses it in an optimal fashion, both performance and feature-wise.
One does not need to understand the internals of the renderer to get good performance. However, it might help when integrating with the scene graph or to figure out why it is not possible to squeeze the maximum efficiency
out of the graphics chip.
Note: Even in the case where every frame is unique and everything is uploaded from scratch, the default renderer will perform well.
The Qt Quick items in a QML scene populate a tree of QSGNode instances. Once created, this tree is a complete description of how a certain frame should be rendered. It does not contain any
references back to the Qt Quick items at all and will on most platforms be processed and rendered in a separate thread. The renderer is a self contained part of the scene graph which traverses the QSGNode tree and uses geometry defined in QSGGeometryNode and shader state defined in QSGMaterial to update the graphics state and
generate draw calls.
If needed, the renderer can be completely replaced using the internal scene graph back-end API. This is mostly interesting for platform vendors who wish to take advantage of non-standard hardware features. For the majority
of use cases, the default renderer will be sufficient.
The default renderer focuses on two primary strategies to optimize the rendering: Batching of draw calls, and retention of geometry on the GPU.
Batching
Whereas a traditional 2D API, such as QPainter, Cairo or Context2D, is written to handle thousands of individual draw calls per frame, OpenGL and
other hardware accelerated APIs perform best when the number of draw calls is very low and state changes are kept to a minimum.
Note: While OpenGL is used as an example in the following sections, the same concepts apply to other graphics APIs as well.
Consider the following use case:

The simplest way of drawing this list is on a cell-by-cell basis. First, the background is drawn. This is a rectangle of a specific color. In OpenGL terms this means selecting a shader program to do solid color fills,
setting up the fill color, setting the transformation matrix containing the x and y offsets and then using for instance glDrawArrays to draw two triangles making up the rectangle. The icon is drawn
next. In OpenGL terms this means selecting a shader program to draw textures, selecting the active texture to use, setting the transformation matrix, enabling alpha-blending and then using for instance glDrawArrays to draw the two triangles making up the bounding rectangle of the icon. The text and separator line between cells follow a similar pattern. And this process is repeated for every cell in the list, so
for a longer list, the overhead imposed by OpenGL state changes and draw calls completely outweighs the benefit that using a hardware accelerated API could provide.
When each primitive is large, this overhead is negligible, but in the case of a typical UI, there are many small items which add up to a considerable overhead.
The default scene graph renderer works within these limitations and will try to merge individual primitives together into batches while preserving the exact same visual result. The result is fewer OpenGL state changes and a
minimal amount of draw calls, resulting in optimal performance.
Opaque Primitives
The renderer separates between opaque primitives and primitives which require alpha blending. By using OpenGL's Z-buffer and giving each primitive a unique z position, the renderer can freely reorder opaque primitives
without any regard for their location on screen and which other elements they overlap with. By looking at each primitive's material state, the renderer will create opaque batches. From Qt Quick core item set, this includes
Rectangle items with opaque colors and fully opaque images, such as JPEGs or BMPs.
Another benefit of using opaque primitives is that opaque primitives do not require GL_BLEND to be enabled, which can be quite costly, especially on mobile and embedded GPUs.
Opaque primitives are rendered in a front-to-back manner with glDepthMask and GL_DEPTH_TEST enabled. On GPUs that internally do early-z checks, this means that the
fragment shader does not need to run for pixels or blocks of pixels that are obscured. Beware that the renderer still needs to take these nodes into account and the vertex shader is still run for every vertex in these
primitives, so if the application knows that something is fully obscured, the best thing to do is to explicitly hide it using Item::visible or Item::opacity.
Note: The Item::z is used to control an Item's stacking order relative to its siblings. It has no direct relation to the renderer and OpenGL's Z-buffer.
Alpha Blended Primitives
Once opaque primitives have been drawn, the renderer will disable glDepthMask, enable GL_BLEND and render all alpha blended primitives in a back-to-front manner.
Batching of alpha blended primitives requires a bit more effort in the renderer as elements that are overlapping need to be rendered in the correct order for alpha blending to look correct. Relying on the Z-buffer alone is
not enough. The renderer does a pass over all alpha blended primitives and will look at their bounding rect in addition to their material state to figure out which elements can be batched and which can not.

In the left-most case, the blue backgrounds can be drawn in one call and the two text elements in another call, as the texts only overlap a background which they are stacked in front of. In the right-most case, the
background of "Item 4" overlaps the text of "Item 3" so in this case, each of backgrounds and texts needs to be drawn using separate calls.
Z-wise, the alpha primitives are interleaved with the opaque nodes and may trigger early-z when available, but again, setting Item::visible to false is always faster.
Mixing with 3D Primitives
The scene graph can support pseudo 3D and proper 3D primitives. For instance, one can implement a "page curl" effect using a ShaderEffect or implement a bumpmapped torus using
QSGGeometry and a custom material. While doing so, one needs to take into account that the default renderer already makes use of the depth buffer.
The renderer modifies the vertex shader returned from QSGMaterialShader::vertexShader() and compresses the z values of the vertex after the model-view and projection matrices have been applied and then adds a small
translation on the z to position it the correct z position.
The compression assumes that the z values are in the range of 0 to 1.
Texture Atlas
The active texture is a unique OpenGL state, which means that multiple primitives using different OpenGL textures cannot be batched. The Qt Quick scene graph, for this reason, allows multiple QSGTexture instances to be allocated as smaller sub-regions of a larger texture; a texture atlas.
The biggest benefit of texture atlases is that multiple QSGTexture instances now refer to the same OpenGL texture instance. This makes it possible to batch textured draw calls as well, such
as Image items, BorderImage items, ShaderEffect items and also C++ types such as QSGSimpleTextureNode and custom QSGGeometryNodes using textures.
Note: Large textures do not go into the texture atlas.
Atlas based textures are created by passing QQuickWindow::TextureCanUseAtlas to the QQuickWindow::createTextureFromImage().
The scene graph uses heuristics to figure out how large the atlas should be and what the size threshold for being entered into the atlas is. If different values are needed, it is possible to override them using the
environment variables QSG_ATLAS_WIDTH=[width], QSG_ATLAS_HEIGHT=[height] and QSG_ATLAS_SIZE_LIMIT=[size]. Changing these values will mostly be
interesting for platform vendors.
Batch Roots
In addition to merging compatible primitives into batches, the default renderer also tries to minimize the amount of data that needs to be sent to the GPU for every frame. The default renderer identifies subtrees which
belong together and tries to put these into separate batches. Once batches are identified, they are merged, uploaded and stored in GPU memory, using Vertex Buffer Objects.
Each Qt Quick Item inserts a QSGTransformNode into the scene graph tree to manage its x, y, scale or rotation. Child items will be populated under this transform node. The default
renderer tracks the state of transform nodes between frames and will look at subtrees to decide if a transform node is a good candidate to become a root for a set of batches. A transform node which changes between frames and
which has a fairly complex subtree can become a batch root.
QSGGeometryNodes in the subtree of a batch root are pre-transformed relative to the root on the CPU. They are then uploaded and retained on the GPU. When the transform changes, the renderer only needs to update the matrix of
the root, not each individual item, making list and grid scrolling very fast. For successive frames, as long as nodes are not being added or removed, rendering the list is effectively for free. When new content enters the
subtree, the batch that gets it is rebuilt, but this is still relatively fast. There are usually several unchanging frames for every frame with added or removed nodes when panning through a grid or list.
Another benefit of identifying transform nodes as batch roots is that it allows the renderer to retain the parts of the tree that have not changed. For instance, say a UI consists of a list and a button row. When the list is
being scrolled and delegates are being added and removed, the rest of the UI, the button row, is unchanged and can be drawn using the geometry already stored on the GPU.
The node and vertex threshold for a transform node to become a batch root can be overridden using the environment variables QSG_RENDERER_BATCH_NODE_THRESHOLD=[count] and QSG_RENDERER_BATCH_VERTEX_THRESHOLD=[count]. Overriding these flags will be mostly useful for platform vendors.
Note: Beneath a batch root, one batch is created for each unique set of material state and geometry type.
Clipping
When setting Item::clip to true, it will create a QSGClipNode with a rectangle in its geometry. The default renderer will apply this clip
by using scissoring in OpenGL. If the item is rotated by a non-90-degree angle, the OpenGL's stencil buffer is used. Qt Quick Item only supports setting a rectangle as clip through QML, but the scene graph API and the default
renderer can use any shape for clipping.
When applying a clip to a subtree, that subtree needs to be rendered with a unique OpenGL state. This means that when Item::clip is true, batching of that item is limited to
its children. When there are many children, like a ListView or GridView, or complex children, like a TextArea, this is fine. One should, however, use clip on smaller items with caution as it prevents batching. This includes button label, text field or list delegate and table cells.
Clipping a Flickable (or item view) can often be avoided by arranging the UI so that opaque items cover areas around the Flickable, and otherwise relying on the window edges to clip everything else.
Setting Item::clip to true also sets the QQuickItem::ItemIsViewport flag; child items with the
QQuickItem::ItemObservesViewport flag may use the viewport for a rough pre-clipping step: e.g. Text omits lines of text that are completely
outside the viewport. Omitting scene graph nodes or limiting the vertices is an optimization, which can be achieved by setting the flags in
C++ rather than setting Item::clip in QML.
When implementing QQuickItem::updatePaintNode() in a custom item, if it can render a lot of details over a large geometric area, you should think about whether it's efficient
to limit the graphics to the viewport; if so, you can set the ItemObservesViewport flag and read the currently exposed area from QQuickItem::clipRect(). One consequence is that updatePaintNode() will be called more often (typically once per frame whenever content is moving in the viewport).
Vertex Buffers
Each batch uses a vertex buffer object (VBO) to store its data on the GPU. This vertex buffer is retained between frames and updated when the part of the scene graph that it represents changes.
By default, the renderer will upload data into the VBO using GL_STATIC_DRAW. It is possible to select different upload strategy by setting the environment variable QSG_RENDERER_BUFFER_STRATEGY=[strategy]. Valid values are stream and dynamic. Changing this value is mostly useful for platform vendors.
Antialiasing
The scene graph supports two types of antialiasing. By default, primitives such as rectangles and images will be antialiased by adding more vertices along the edge of the primitives so that the edges fade to transparent. We
call this method vertex antialiasing. If the user requests a multisampled OpenGL context, by setting a QSurfaceFormat with samples greater than 0 using
QQuickWindow::setFormat(), the scene graph will prefer multisample based antialiasing (MSAA). The two techniques will affect how the rendering happens internally and have different
limitations.
It is also possible to override the antialiasing method used by setting the environment variable QSG_ANTIALIASING_METHOD to either vertex or msaa.
Vertex antialiasing can produce seams between edges of adjacent primitives, even when the two edges are mathematically the same. Multisample antialiasing does not.
Vertex Antialiasing
Vertex antialiasing can be enabled and disabled on a per-item basis using the Item::antialiasing property. It will work regardless of what the underlying hardware
supports and produces higher quality antialiasing, both for normally rendered primitives and also for primitives captured into framebuffer objects, for instance using the ShaderEffectSource type.
The downside to using vertex antialiasing is that each primitive with antialiasing enabled will have to be blended. In terms of batching, this means that the renderer needs to do more work to figure out if the primitive can
be batched or not and due to overlaps with other elements in the scene, it may also result in less batching, which could impact performance.
On low-end hardware blending can also be quite expensive so for an image or rounded rectangle that covers most of the screen, the amount of blending needed for the interior of these primitives can result in significant
performance loss as the entire primitive must be blended.
Multisample Antialiasing
Multisample antialiasing is a hardware feature where the hardware calculates a coverage value per pixel in the primitive. Some hardware can multisample at a very low cost, while other hardware may need both more memory and
more GPU cycles to render a frame.
Using multisample antialiasing, many primitives, such as rounded rectangles and image elements can be antialiased and still be opaque in the scene graph. This means the renderer has an easier job when creating batches
and can rely on early-z to avoid overdraw.
When multisample antialiasing is used, content rendered into framebuffer objects need additional extensions to support multisampling of framebuffers. Typically GL_EXT_framebuffer_multisample and
GL_EXT_framebuffer_blit. Most desktop chips have these extensions present, but they are less common in embedded chips. When framebuffer multisampling is not available in the hardware, content
rendered into framebuffer objects will not be antialiased, including the content of a ShaderEffectSource.
As stated in the beginning, understanding the finer details of the renderer is not required to get good performance. It is written to optimize for common use cases and will perform quite well under almost any
circumstances.
- Good performance comes from effective batching, with as little as possible of the geometry being uploaded again and again. By setting the environment variable
QSG_RENDERER_DEBUG=render, the
renderer will output statistics on how well the batching goes, how many batches are used, which batches are retained and which are opaque and not. When striving for optimal performance, uploads should happen only when really
needed, batches should be fewer than 10 and at least 3-4 of them should be opaque.
- The default renderer does not do any CPU-side viewport clipping nor occlusion detection. If something is not supposed to be visible, it should not be shown. Use
Item::visible: false for items
that should not be drawn. The primary reason for not adding such logic is that it adds additional cost which would also hurt applications that took care in behaving well.
- Make sure the texture atlas is used. The Image and BorderImage items will use it unless the image is too large. For textures created in C++, pass QQuickWindow::TextureCanUseAtlas when calling QQuickWindow::createTexture(). By setting the environment variable
QSG_ATLAS_OVERLAY all atlas
textures will be colorized so they are easily identifiable in the application.
- Use opaque primitives where possible. Opaque primitives are faster to process in the renderer and faster to draw on the GPU. For instance, PNG files will often have an alpha channel, even though each pixel is fully
opaque. JPG files are always opaque. When providing images to a QQuickImageProvider or creating images with QQuickWindow::createTextureFromImage(), let the image have QImage::Format_RGB32, when possible.
- Be aware of that overlapping compound items, like in the illustration above, cannot be batched.
- Clipping breaks batching. Never use on a per-item basis, inside table cells, item delegates or similar. Instead of clipping text, use eliding. Instead of clipping an image, create a
QQuickImageProvider that returns a cropped image.
- Batching only works for 16-bit indices. All built-in items use 16-bit indices, but a custom geometry is free to also use 32-bit indices.
- Some material flags prevent batching, the most limiting one being QSGMaterial::RequiresFullMatrix which prevents all batching.
- Applications with a monochrome background should set it using QQuickWindow::setColor() rather than using a top-level Rectangle item. QQuickWindow::setColor() will be used in a call to
glClear(), which is potentially faster.
- Mipmapped Image items are not placed in the global atlas and will not be batched.
- A bug in the OpenGL driver related to framebuffer object (FBO) readbacks may corrupt rendered glyphs. If you set the
QML_USE_GLYPHCACHE_WORKAROUND environment variable, Qt keeps an additional
copy of the glyph in RAM. This means that performance is slightly lower when drawing glyphs that have not been drawn before, as Qt accesses the extra copy via the CPU. It also means that the glyph cache will use twice as much
memory. The quality is not affected by this.
If an application performs poorly, make sure that rendering is actually the bottleneck. Use a profiler! The environment variable QSG_RENDER_TIMING=1 will output a number of useful timing
parameters which can be useful in pinpointing where a problem lies.
Visualizing
To visualize the various aspects of the scene graph's default renderer, the QSG_VISUALIZE environment variable can be set to one of the values detailed in each section below. We provide examples
of the output of some of the variables using the following QML code:
import QtQuick 2.2
Rectangle {
width: 200
height: 140
ListView {
id: clippedList
x: 20
y: 20
width: 70
height: 100
clip: true
model: ["Item A", "Item B", "Item C", "Item D"]
delegate: Rectangle {
color: "lightblue"
width: parent.width
height: 25
Text {
text: modelData
anchors.fill: parent
horizontalAlignment: Text.AlignHCenter
verticalAlignment: Text.AlignVCenter
}
}
}
ListView {
id: clippedDelegateList
x: clippedList.x + clippedList.width + 20
y: 20
width: 70
height: 100
clip: true
model: ["Item A", "Item B", "Item C", "Item D"]
delegate: Rectangle {
color: "lightblue"
width: parent.width
height: 25
clip: true
Text {
text: modelData
anchors.fill: parent
horizontalAlignment: Text.AlignHCenter
verticalAlignment: Text.AlignVCenter
}
}
}
}
For the ListView on the left, we set its clip property to true. For the ListView on right, we also set each delegate's clip property to true to illustrate the effects of clipping on
batching.
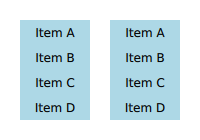
Original
Note: The visualized elements do not respect clipping, and rendering order is arbitrary.
Visualizing Batches
Setting QSG_VISUALIZE to batches visualizes batches in the renderer. Merged batches are drawn with a solid color and unmerged batches are drawn with a diagonal line
pattern. Few unique colors means good batching. Unmerged batches are bad if they contain many individual nodes.

QSG_VISUALIZE=batches
Visualizing Clipping
Setting QSG_VISUALIZE to clip draws red areas on top of the scene to indicate clipping. As Qt Quick Items do not clip by default, no clipping is usually visualized.
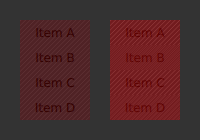
QSG_VISUALIZE=clip
Visualizing Changes
Setting QSG_VISUALIZE to changes visualizes changes in the renderer. Changes in the scenegraph are visualized with a flashing overlay of a random color. Changes on a
primitive are visualized with a solid color, while changes in an ancestor, such as matrix or opacity changes, are visualized with a pattern.
Visualizing Overdraw
Setting QSG_VISUALIZE to overdraw visualizes overdraw in the renderer. Visualize all items in 3D to highlight overdraws. This mode can also be used to detect geometry
outside the viewport to some extent. Opaque items are rendered with a green tint, while translucent items are rendered with a red tint. The bounding box for the viewport is rendered in blue. Opaque content is easier for the
scenegraph to process and is usually faster to render.
Note that the root rectangle in the code above is superfluous as the window is also white, so drawing the rectangle is a waste of resources in this case. Changing it to an Item can give a slight performance boost.

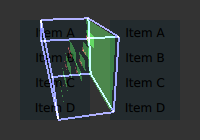
QSG_VISUALIZE=overdraw
Rendering via the Qt Rendering Hardware Interface
From Qt 6.0 onwards, the default adaptation always renders via a graphics abstraction layer, the Qt Rendering Hardware Interface (RHI), provided by the Qt GUI module. This means that,
unlike Qt 5, no direct OpenGL calls are made by the scene graph. Rather, it records resource and draw commands by using the RHI APIs, which then translate the command stream into OpenGL, Vulkan, Metal, or Direct 3D calls.
Shader handling is also unified by writing shader code once, compiling to SPIR-V, and then translating to the language appropriate for the various graphics APIs.
To control the behavior, the following environment variables can be used:
| Environment Variable |
Possible Values |
Description |
QSG_RHI_BACKEND |
vulkan, metal, opengl, d3d11, d3d12 |
Requests the specific RHI backend. By default the targeted graphics API is chosen based on the platform, unless overridden by this variable or the equivalent C++ APIs. The defaults are currently Direct3D 11 for
Windows, Metal for macOS, OpenGL elsewhere. |
QSG_INFO |
1 |
Like with the OpenGL-based rendering path, setting this enables printing system information when initializing the Qt Quick scene graph. This can be very useful for troubleshooting. |
QSG_RHI_DEBUG_LAYER |
1 |
Where applicable (Vulkan, Direct3D), enables the graphics API implementation's debug or validation layers, if available, either on the graphics device or the instance object. For Metal on macOS, set the environment
variable METAL_DEVICE_WRAPPER_TYPE=1 instead. |
QSG_RHI_PREFER_SOFTWARE_RENDERER |
1 |
Requests choosing an adapter or physical device that uses software-based rasterization. Applicable only when the underlying API has support for enumerating adapters (for example, Direct3D or Vulkan), and is ignored
otherwise. |
Applications wishing to always run with a single given graphics API, can request this via C++ as well. For example, the following call made early in main(), before constructing any QQuickWindow, forces the use of Vulkan (and will fail otherwise):
QQuickWindow::setGraphicsApi(QSGRendererInterface::Vulkan);
See QSGRendererInterface::GraphicsApi. The enum values OpenGL, Vulkan, Metal,
Direct3D11, Direct3D12 are equivalent in effect to running with QSG_RHI_BACKEND set to the equivalent string key.
All QRhi backends will choose the system default GPU adapter or physical device, unless overridden by QSG_RHI_PREFER_SOFTWARE_RENDERER or a backend-specific variable,
such as, QT_D3D_ADAPTER_INDEX or QT_VK_PHYSICAL_DEVICE_INDEX. No further adapter configurability is provided at this time.
Starting with Qt 6.5, some of the settings that were previously only exposed as environment variables are available as C++ APIs in QQuickGraphicsConfiguration. For example,
setting QSG_RHI_DEBUG_LAYER and calling setDebugLayer(true) are equivalent.


